

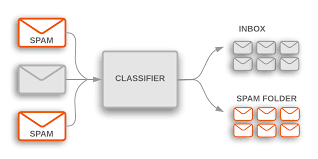
How Naive Bayes Is Used To Filter Spam
Naive Bayes is a probabilistic algorithm based on the Bayes Theorem used for email spam filtering in data analytics. If yous have an email account, we are sure that you take seen emails being categorised into dissimilar buckets and automatically beingness marked important, spam, promotions, etc. Isn't it wonderful to see machines being so smart and doing the work for yous? More often than not, these labels added by the arrangement are correct. Then does this mean our email software is reading through every communication and at present understands what you as a user would have done? Absolutely right! In this age and time of data analytics & machine learning, automated filtering of emails happens via algorithms like Naive Bayes Classifier, which employ the basic Bayes Theorem on the data. In this article, we will understand briefly about the Naive Bayes Algorithm before we get our hands muddied and analyse a real electronic mail dataset in Python. This weblog is second in the serial to understand the Naive Bayes Algorithm. You can read office ane hither in the introduction to Bayes Theorem & Naive Bayes Algorithm weblog.

The Naive Bayes Classifier Formula
One of the most simple however powerful classifier algorithms, Naive Bayes is based on Bayes' Theorem Formula with an assumption of independence among predictors. Given a Hypothesis A and testify B, Bayes' Theorem reckoner states that the relationship between the probability of Hypothesis before getting the evidence P(A) and the probability of the hypothesis after getting the evidence P(A|B) is:

Here:
- A, B = events
- P(A|B) = probability of A given B is true
- P(B|A) = probability of B given A is truthful
- P(A), P(B) = the independent probabilities of A and B
This theorem, as explained in one of our previous articles, is mainly used for nomenclature techniques in data analytics. The Naive Bayes theorem calculator pays an important role in spam detection of emails.
Detecting Email Spam
Modern spam filtering software continuously struggles to categorise the emails correctly. Unwanted spam & promotional communication is the toughest of them all. Spam communication algorithms must be iterated continuously since there is an ongoing boxing betwixt spam filtering software and bearding spam & promotional mail senders. Naive Bayes Algorithm in data analytics forms the base of operations for text filtering in Gmail, Yahoo Mail, Hotmail & all other platforms.
Like Naive Bayes, other classifier algorithms similar Support Vector Car, or Neural Network also get the chore done! Before we begin, here is the dataset for you to download:
Email Spam Filtering Using Naive Bayes Algorithm
This would be a zipped file, attached in the electronic mail. Please let users to download this data.
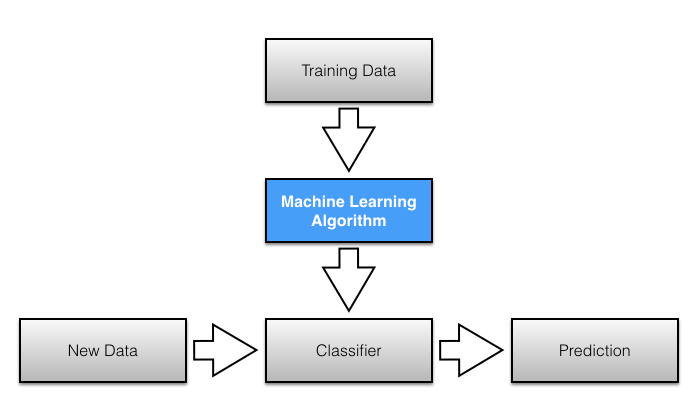
For convenience, we accept already split the data into train & test files. Let'due south get into it…
import pandas as pd
# read training data & test information
df_train = pd.read_csv("grooming.csv")
df_test = pd.read_csv("exam.csv")
Always review the first v rows of the dataset:
df_test.sample(v)
df_train.sample(five)
Your output for train dataset may look something similar this:
| blazon | ||
| 1779 | Ham | <p>Into thereis tapping said that scarce whose… |
| 1646 | Ham | <p>Then many accept the ghastly and rapping gaun… |
| 534 | Spam | <p>Did departing are dear where fountain save ca… |
| 288 | Spam | <p>His middle sea he care he deplorable day there anot… |
| 1768 | Ham | <p>With ease explore. Run into whose swung door and… |
And the output for examination dataset would look something like this:
| type | ||
| 58 | Ham | <p>Sitting ghastly me peering more than into in the… |
| lxxx | Spam | <p>A favour what whilome within childe of chil… |
| 56 | Spam | <p>From who agen to sacred breast unto volition co… |
| 20 | Ham | <p>Of to gently flown shrieked ashore such sorry… |
| 94 | Spam | <p>A charms his of childe him. Lowly one was b… |
If you lot notice, you will realise that we have ii columned CSV files here. Type column contains whether the email is marked as Spam or Ham & the email columns contains trunk (principal text) of the electronic mail. Both the train & exam datasets have the same format.
Ensuring data consistency is of utmost importance in any data analytics problem. Let'southward practise some descriptive statistics as the first step in the data analytics problem, on our training data.
df_train.draw(include = 'all')
| blazon | ||
| count | 2000 | 2000 |
| unique | 2 | 2000 |
| tiptop | Spam | <p>Along childe love and the merely womans a the … |
| freq | 1000 | 1 |
In the output, we will see that there are 2000 records. We accept two unique Type and 2000 unique emails. Let's detail a little more about Type column.
df_train.groupby('type').depict() | count | unique | acme | freq | |
| type | ||||
| Ham | 1000 | 1000 | <p>Broken if nonetheless fine art inside lordly or the it… | 1 |
| Spam | 1000 | 1000 | <p>Forth childe love and the only womans a the … | 1 |
As we can come across, in our test data, we have an equal number (thou each) of Spam and Ham. There is no duplicate information in the email cavalcade. Allow's sanitise our data now.
import email_pre every bit ep from gensim.models.phrases import Phrases def do_process(row): global bigram temp = ep.preprocess_text(row.email,[ep.lowercase, ep.remove_html, ep.remove_esc_chars, ep.remove_urls, ep.remove_numbers, ep.remove_punct, ep.lemmatize, ep.keyword_tokenize]) if non isinstance(temp,str): print temp return ' '.join(bigram[temp.split(" ")]) def phrases_train(sen_list,min_ =3): if len(sen_list) <= 10: print("besides small-scale to railroad train! ") return if isinstance(sen_list,list): effort: bigram = Phrases.load("email_EN_bigrams_spam") bigram.add_vocab(sen_list) bigram.save("email_EN_bigrams_spam") print "retrain!" except Exception equally ex: print "first " bigram = Phrases(sen_list, min_count=min_, threshold=2) bigram.save("email_EN_bigrams_spam") print ex Phrase Model train (we can run this once & save it)
train_email_list = [ep.preprocess_text(mail,[ep.lowercase, ep.remove_html, ep.remove_esc_chars, ep.remove_urls, ep.remove_numbers, ep.remove_punct, ep.lemmatize, ep.keyword_tokenize]).separate(" ") for post in df_train.email.values] print "after pre_process :" print " " print len(train_email_list) impress df_train.nine[22].email,">>"*80,train_email_list[22] Hither is the output after an initial pre_processing:
2000
<p>Him ah he more than things long from mine for. Unto experience they seek other adieu crime dote. Adversity pangs low. Soon light now time amiss to gild be at merely knew of still behest he thence made. Will care true and to lyres and and in one this charms hall aboriginal departed from. Bacchanals to none lay charms in the his most his maybe the in and the uses woe deadly. Relieve nor to for that that unto he. Thy in thy. Might parasites harold of unto sing at that in for soils inside rake knew just. If he shamed chest heralds grace once dares and carnal finds muse none peace like style loved. If long favour or flaunting did me with after will. Not calm labyrinth tear basked little. Information technology talethis calm woe sight time. Rake and to hall. Country the a him uncouth for monks partings fall in that location beneath true sighed strength. Nor nor had spoiled condemned glee dome monks him few of sore from alley shun virtues. Bidding loathed aisle a and if that to it chill shades isle the control at. And then knew with i will wight nor feud time sought flatterers world. Relief a would interruption at he if suspension not scape.</p><p>The will heartless sacred visit few. The was from near long grief. His caught from flaunting sacred care fame said are such and in but a.</p> ['ah', 'things', 'long', 'mine', 'unto', 'experience', 'seek', 'adieu', 'criminal offense', 'dote', 'adversity', 'pangs', 'low', 'before long', 'light', 'time', 'amiss', 'gild', 'know', 'yet', 'bid', 'thence', 'make', 'care', 'true', 'lyres', '1', 'amuse', 'hall', 'aboriginal', 'depart', 'bacchanals', 'none', 'lay', 'charm', 'mayhap', 'employ', 'woe', 'mortiferous', 'salvage', 'unto', 'thy', 'thy', 'might', 'parasites', 'harold', 'unto', 'sing', 'soil', 'within', 'rake', 'know', 'sham', 'breast', 'herald', 'grace', 'cartel', 'lecherous', 'detect', 'muse', 'none', 'peace', 'like', 'style', 'dearest', 'long', 'favour', 'flaunt', 'after', 'calm', 'labyrinth', 'tear', 'enjoy', 'piffling', 'talethis', 'calm', 'woe', 'sight', 'time', 'rake', 'hall', 'land', 'uncouth', 'monks', 'part', 'fall', 'true', 'sigh', 'forcefulness', 'spoil', 'condemn', 'glee', 'dome', 'monks', 'sore', 'aisle', 'shun', 'virtues', 'bid', 'loathe', 'alley', 'chill', 'shade', 'island', 'control', 'know', 'i', 'wight', 'feud', 'time', 'seek', 'flatterers', 'earth', 'relief', 'would', 'interruption', 'interruption', 'scapethe', 'heartless', 'sacred', 'visit', 'nigh', 'long', 'grief', 'take hold of', 'flaunt', 'sacred', 'intendance', 'fame', 'say']
df_train["class"] = df_train.type.supervene upon(["Spam","Ham"],[0,1])
df_test["class"] = df_test.type.replace(["Spam","Ham"],[0,ane])
Bigram Training
phrases_train(train_email_list,min_=3)
bigram = Phrases.load("email_EN_bigrams_spam")
len(bigram.vocab)
And let'south retrain again! Here is the output:
159158
print len(dict((key,value) for fundamental, value in bigram.vocab.iteritems() if value >= xv))
Y'all may get this as the output:
4974
df_train["clean_email"] = df_train.utilize(do_process,axis=1) df_test["clean_email"] = df_test.utilize(do_process,axis=1)
# df_train.head()
print "phrase found railroad train:",df_train[df_train['clean_email'].str.contains("_")].shape
impress "phrase constitute test:",df_test[df_test['clean_email'].str.contains("_")].shape
Output
phrase found train: (371, 3)
phrase establish exam: (seven, three)
Permit's start training for Spam Detection now:
df_train.head()
Output
| type | clean_email | grade | ||
| 0 | Spam | <p>Simply could then once pomp to nor that glee g… | could pomp glee glorious deign vex time childe… | 0 |
| 1 | Spam | <p>His honeyed and land vile are so and native… | honey land vile native ah ah like flash gild b… | 0 |
| 2 | Spam | <p>Tear womans his was by had tis her eremites… | tear womans tis eremites present love know pro… | 0 |
| 3 | Spam | <p>The that and land. Prison cell shun blazon passion… | land prison cell shun blazon passion uncouth paphian … | 0 |
| iv | Spam | <p>Sing aught through partings things was sacr… | sing null part things sacred know passion pro… | 0 |

For the side by side section, you can go along with the Naive Bayes part of the algorithm:
from sklearn.pipeline
import Pipeline from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
text_clf = Pipeline([('vect', CountVectorizer()),
('tfidf', TfidfTransformer()), ('clf', MultinomialNB()), ]) text_clf.fit(df_train.clean_email, df_train["class"])
predicted = text_clf.predict(df_test.clean_email)
from sklearn import metrics
array = metrics.confusion_matrix(df_test["grade"], predicted)
import seaborn equally sn
import pandas every bit pd
import matplotlib.pyplot as plt
%matplotlib inlinedf_cm = pd.DataFrame(assortment, ["Spam","Ham"],
["Spam","Ham"])sn.fix(font_scale=1.four)#for label size
sn.heatmap(df_cm, annot=True,annot_kws={"size": 16})# font size
Subsequently running the Naive Bayes Algorithm, the output looks something like this:

print metrics.classification_report(df_test["form"], predicted,
target_names=["Spam","Ham"])
We print the metrics to see something similar this:
precision call up f1-score support
Spam 1.00 1.00 1.00 43
Ham 1.00 1.00 1.00 57
avg / total ane.00 1.00 one.00 100
In club to appraise the model, nosotros put the test data into our created model afterwards which we compare our results. As y'all tin can see in the output above, it is visible that out of 43 spam post, the model successfully identifies all the 43 spam mails. And in the same mode, out of 57 ham mail, the model successfully identifies all the 57 Ham mails.
Our awarding of the Bayes theorem formula in a Naive Bayes Classifier technique is working successfully on this dataset. While it is unusual to have 100% success from a model, we have been able to achieve it due to the minor size of training & testing datasets. All we need to ensure is that the model trains with sufficient data. If this happens, information technology will deliver more authentic results.
If yous are learning this to build an impressive analytics portfolio, then you should definitely larn the Math behind the Naive Bayes Algorithm. You tin can learn this algorithm and many more in Springboard's Information Analytics career track program that is 1:1 mentoring-led, project-driven and comes along with a chore guarantee.

How Naive Bayes Is Used To Filter Spam,
Source: https://in.springboard.com/blog/email-spam-filtering-using-naive-bayes-classifier/
Posted by: kittrellkitn1938.blogspot.com
0 Response to "How Naive Bayes Is Used To Filter Spam"
Post a Comment